OCI データ統合エラー対処
Oracle Cloud Infrasatructureのデータ統合サービスを使い始めとあるエラーで苦戦したので備忘録として残そうと思います。
エラー{そんなバケットないよ~}
データ統合サービスのデータアセットでアセット元にオブジェクトストレージ内のCSVファイルを指定し、データ参照できるか確認したところ下記エラーに出会いました。
バケットが無いって言ってるわけですが、こちらからするとちゃんと用意したんで無いわけ無いんですよね(笑)

解決策
下記ポリシーを追加する事で解決しました。
結局権限が無いのでオブジェクトを参照できなかったんですよね。。。
Allow group <group_name> to use objects in compartment <compartment_name>
allow any-user to manage objects in compartment <compartment> where ALL {request.principal.type = 'disworkspace'}もしかすると上記2つのポリシー設定しても参照できない場合もあります。
その場合は他のポリシーが無くて参照出来ない可能性が考えられます。
そんな時は公式ドキュメントをご確認ください。
シェルワンライナー ~シェル芸を極める道~ 3歩目
sortとuniqによる集計
問 14.前回のおさらい
出力される1~5の数字に対して奇数、偶数を判定する
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}'
奇数
偶数
奇数
偶数
奇数
[opc@linux ~]$ ↓のように書いても良いが、【条件 ? 条件が正の場合:条件が偽の場合】と記述することができ、見た目ものスッキリすので覚えておいて損はない
seq 5 | awk '$1%2{print "奇数"}$1%2{print "偶数"}'
問 15.sortを使った並び替え
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}' | sort
偶数
偶数
奇数
奇数
奇数
[opc@linux ~]$
問 16.uniqを使ったカウント
uniqのオプション-cをつけることでカウントしている
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}' | sort | uniq -c
2 偶数
3 奇数
[opc@linux ~]$
豆知識
uniqは出力が連続した値同士で並んでいる必要がある。
↓のようにsortせずにバラバラの状態でuniqを使うとそれぞれでカウントされる
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}' | uniq -c
1 奇数
1 偶数
1 奇数
1 偶数
1 奇数
[opc@linux ~]$
17.問14~16を工夫して奇数偶数をカウントする
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}' | sort | uniq -c | awk '{print $2,$1}'
偶数 2
奇数 3
[opc@linux ~]$ 別解
a[$1]の連想配列を使った別解になります。
[opc@linux ~]$ seq 5 | awk '{print $1%2 ? "奇数":"偶数"}' | awk '{a[$1]++}END{for(k in a)print k,a[k]}'
奇数 3
偶数 2
[opc@linux ~]$
Oracle Machine Learning AutoMLを使った機械学習
Autonomous Data Warehouse触ってみるの続きで今回は「Oracle Machine Learning AutoML」を使ってみたいと思います。
今回機械学習するデータはKaggleのチュートリアルで有名なタイタニックのデータを利用します。
前提条件
- Autonomous Data Warehouseが構築されていること
- タイタニックのデータを入手済みであること
タイタニックのデータをADWにアップロードする
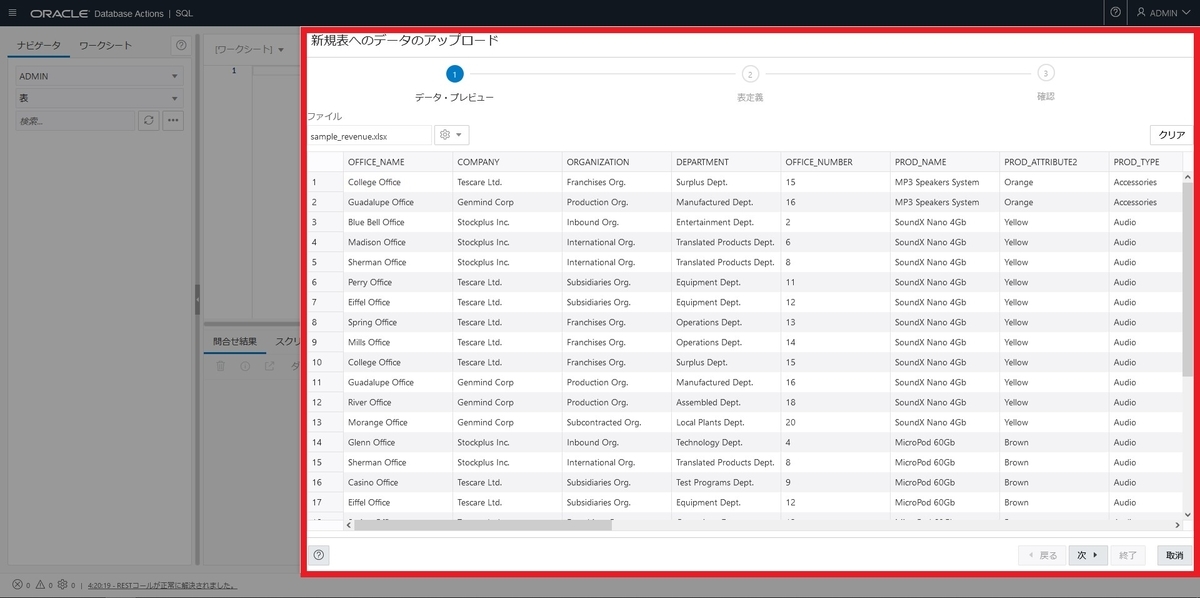
SQL Developer Webの【データベースアクション】にアクセスし、【データ・ロード】をクリックします。

【データのロード】と【ローカル・ファイル】を選択し、【次】へ進みます

タイタニックのデータをドラッグ&ドロップでアップロードします

アップロード後、【鉛筆マーク】をクリックするとCSVデータを確認することができる

↓

今回は【Servived】をVARCHAR2にデータ型を変更し、【閉じる】へ

その後データに問題なければ【開始ボタン】を押しデータを流し込む

【実行】をクリック

問題なくデータを取り込めたことを確認する

同じ要領でtest.csvもアップロードする

Oracle Machine Learning AutoML UIでモデル作成とデプロイ
OCI管理画面に戻り、【サービス・コンソール】をクリックする

左タブの【開発】から【Oracle Machine Learning ユーザー・インタフェース】へ

ログインユーザを求められた際は下記手順でユーザを作成する
すでにユーザを作成済みであればそのユーザでログインする
kyamisama.hatenablog.com
【AutoML】をクリック

【作成】をクリック

【名前】、【コメント】を入力後【データ・ソース】の虫眼鏡マークをクリックする

【TRAIN】を選択します

【学習】を[SURVIVED]、【ケースID】を[PASSENGERID]、【学習タイプ】を[分類]にします

画面右上の【開始】ボタンより【より速い結果】を選択します

学習中の画面

学習完了

【リーダー・ボード】を見ることでどのモデルの結果が良かったかが分かる
今回はSVMの精度が良かったとわかる

モデル名をクリックするこで詳細な結果が表示される
予測に最も影響したパラメータ

混同行列の結果

モデルのデプロイをします
対象のモデル名を選択し、【デプロイ】を実行します

デプロイの実行
【名前】、【URI】、【バージョン】、【ネームスペース】を記入し【共有】にチェックを入れる

デプロイの完了

モデル画面に移行

モデルのデプロイ
【デプロイメント】タブをクリックすると、先ほどデプロイしたモデルが表示されます

モデル名をクリックするとモデルのメタデータを見ることが出来る
{
"miningFunction": "CLASSIFICATION",
"algorithm": "SUPPORT_VECTOR_MACHINES",
"attributes": [
{
"name": "AGE",
"attributeType": "NUMERICAL"
},
{
"name": "CABIN",
"attributeType": "CATEGORICAL"
},
{
"name": "EMBARKED",
"attributeType": "CATEGORICAL"
},
{
"name": "FARE",
"attributeType": "NUMERICAL"
},
{
"name": "NAME",
"attributeType": "CATEGORICAL"
},
{
"name": "PARCH",
"attributeType": "NUMERICAL"
},
{
"name": "PCLASS",
"attributeType": "NUMERICAL"
},
{
"name": "SEX",
"attributeType": "CATEGORICAL"
},
{
"name": "SIBSP",
"attributeType": "NUMERICAL"
},
{
"name": "TICKET",
"attributeType": "CATEGORICAL"
}
],
"output": {
"name": "SURVIVED",
"attributeType": "CATEGORICAL"
},
"labels": [
"0",
"1"
],
"modelName": "SVM_Titnic"
}
URIの確認
UTI名をクリックします

URI情報を見ることが出来ます。
"url"と"paths"はメモしておいてください。後ほど使います。
【***.***.***.***】はマスクしています。
{
"openapi": "3.0.1",
"info": {
"title": "SVM_Titnic",
"version": "1"
},
"servers": [
{
"url": "https://***.***.***.***/omlmod/v1/deployment"
}
],
"security": [
{
"BearerAuth": []
}
],
"paths": {
"/SVM_Titnic/score": {
"post": {
"operationId": "scoreModel",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SVM_Titnic_INPUT_TYPE"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successfully scored model SVM_Titnic.",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SVM_Titnic_OUTPUT_TYPE"
}
}
}
},
"400": {
"description": "Bad request.",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
},
"401": {
"description": "Unauthorized.",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
},
"404": {
"description": "Resource not found.",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
},
"500": {
"description": "Problem connecting to db, executing query or other unexpected error.",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
}
}
}
}
},
"components": {
"schemas": {
"SVM_Titnic_INPUT_TYPE": {
"properties": {
"inputRecords": {
"type": "array",
"items": {
"$ref": "#/components/schemas/Attributes"
}
},
"topN": {
"type": "integer",
"format": "int32"
},
"topNdetails": {
"type": "integer",
"format": "int32"
}
}
},
"Attributes": {
"properties": {
"AGE": {
"type": "number",
"format": "double"
},
"CABIN": {
"type": "string"
},
"EMBARKED": {
"type": "string"
},
"FARE": {
"type": "number",
"format": "double"
},
"NAME": {
"type": "string"
},
"PARCH": {
"type": "number",
"format": "double"
},
"PCLASS": {
"type": "number",
"format": "double"
},
"SEX": {
"type": "string"
},
"SIBSP": {
"type": "number",
"format": "double"
},
"TICKET": {
"type": "string"
}
}
},
"SVM_Titnic_OUTPUT_TYPE": {
"properties": {
"scoringResults": {
"type": "array",
"items": {
"$ref": "#/components/schemas/ScoringResults"
}
}
}
},
"ScoringResults": {
"properties": {
"classifications": {
"type": "array",
"items": {
"$ref": "#/components/schemas/LabelProb"
}
},
"details": {
"type": "array",
"items": {
"$ref": "#/components/schemas/Detail"
}
}
}
},
"LabelProb": {
"properties": {
"label": {
"type": "string"
},
"probability": {
"type": "number",
"format": "double"
}
}
},
"Detail": {
"properties": {
"columnName": {
"type": "string"
},
"weight": {
"type": "number",
"format": "double"
}
}
},
"Error": {
"required": [
"code",
"message"
],
"properties": {
"code": {
"type": "string"
},
"message": {
"type": "string"
}
}
}
},
"securitySchemes": {
"BearerAuth": {
"type": "http",
"scheme": "bearer",
"bearerFormat": "JWT"
}
}
}
}
ノートブックを使ってデータを予測してみる
AutoMLにアクセスする

作成したモデルをクリック

精度の高いアルゴリズムを選択しノートブックを起動します

ノートブック起動完了

【ノートブック】へアクセスします

生成したノートブックをクリックします

ノートブックが起動し実行していく

予測の評価指標をみる

シェルワンライナー ~シェル芸を極める道~ 2歩目
awkによる検索と計算の練習
問 10.正規表現を使って偶数を出力する
[opc@linux ~]$ seq 5 | awk '/[24]$/' 2 4
問 11.C言語のような条件式で偶数を出力する
'$1%2==0'の意味は$1が出力行の1つ目の要素を指す。
ここでは2とか4となる。
そして%2==0は2で割って余り0つまり偶数であることを判定している
[opc@linux ~]$ seq 5 | awk '$1%2==0' 2 4
問 12.出力した値(偶数)から半角スペースを置いて「偶数」と出力する
{printf("%s 偶数\n",$1)}の解説。
引数1個目の%sは引数2個目の$1の入れ場所を指している。
[opc@linux ~]$ seq 5 | awk '$1%2==0{printf("%s 偶数\n",$1)}'
2 偶数
4 偶数別解
[opc@linux ~]$ seq 5 | awk '$1%2==0{print $1,"偶数"}'
2 偶数
4 偶数
問 13.条件式を使って全ての値の偶数or奇数を判定し出力する
[opc@linux ~]$ seq 5 | awk '$1%2==0{print $1,"偶数"}$1%2{print $1,"奇数"}'
1 奇数
2 偶数
3 奇数
4 偶数
5 奇数==1を入れてOK
[opc@linux ~]$ seq 5 | awk '$1%2==0{print $1,"偶数"}$1%2==1{print $1,"奇数"}'
1 奇数
2 偶数
3 奇数
4 偶数
5 奇数
問 14.BEGIN構文を使って問13と同じ結果を出力し最後に1から5を合計する
BEGIN,ENDパターンとはawkが1行目の処理を始める前と最終行に処理する内容とそれぞれawkで実行させたい内容を書きます。
ここでのBEGINの{a=0}はaと言う変数を初期化しています。
ENDでは変数aを出力しています。
{a+=$1}は各行の$1の値を足し合わせています。
[opc@linux ~]$ seq 5 | awk 'BEGIN{a=0}$1%2==0{print $1,"偶数"}$1%2{print $1,"奇数"}{a+=$1}END{print "合計",a}'
1 奇数
2 偶数
3 奇数
4 偶数
5 奇数
合計 15
シェルワンライナー ~シェル芸を極める道~ 1歩目
1+1の計算
bcは計算するコマンドで | で左の1+1の結果をbcに渡している
[opc@linux ~]$ echo '1+1' | bc 2 [opc@linux ~]$
ファイルへの保存
>記号を使うことで計算された値をaに書き込む(リダイレクトする)
[opc@linux ~]$ echo '1+1' | bc > a [opc@linux ~]$ cat a 2 [opc@linux ~]$
ファイルのパーミッション
chmod -r [ファイル名]とすることで読み込み出来なくしています。
読み込めるようにするにはchmod +r [ファイル名]とすることで読み込めます。
[opc@linux ~]$ chmod -r a [opc@linux ~]$ cat a cat: a: Permission denied [opc@linux ~]$ chmod +r a [opc@linux ~]$ cat a 2 [opc@linux ~]$
sedによる置換の練習
問1.最初の「エチル」を「メチル」に置換する。
期待する出力結果:クロロメチルエチルエーテル [opc@linux ~]$ echo クロロエチルエチルエーテル |sed 's/エ/メ/' クロロメチルエチルエーテル [opc@linux ~]$
問2.「エチルエ」を「エチルメ」に置換する。
期待する出力結果:クロロエチルメチルエーテル [opc@linux ~]$ echo クロロエチルエチルエーテル |sed 's/エチルエ/エチルメ/' クロロエチルメチルエーテル [opc@linux ~]$
問3.全ての「メ」を「エ」に置換する。
その場合「g」を付ける。
期待する出力結果:クロロエチルエチルエーテル [opc@linux ~]$ echo クロロメチルメチルエーテル |sed 's/メ/エ/g' クロロエチルエチルエーテル [opc@linux ~]$
問4.「エチル」を「エチルエチル」にする
sed 's/エチル/エチルエチル/' でも良いが、&&でも同じ意味になる。
&は「エチル」を指すので「エチルエチル」にするには「&&」となる。
期待する出力結果:クロロエチルエチルエーテル [opc@linux ~]$ echo クロロエチルエーテル | sed 's/エチル/&&/' クロロエチルエチルエーテル [opc@linux ~]$
問5.「メチル」と「エチル」を入れ替える。
オプション-Eを利用し、置換対象部分に()で文字を入れると順番に番号を与えられるのでその番号を使って入れ替える。
[opc@linux ~]$ echo クロロメチルエチルエーテル | sed -E 's/(メチル)(エチル)/\2\1/' クロロエチルメチルエーテル [opc@linux ~]$
grepによる検索の練習
問1.0が1文字でもある場合の検索方法
[opc@linux ~]$ seq 100 | grep 0 | xargs 10 20 30 40 50 60 70 80 90 100
問2.行の先頭が8で始まる場合の検索方法
[opc@linux ~]$ seq 100 | grep '^8' | xargs 8 80 81 82 83 84 85 86 87 88 89
問3.行末が8で終わる場合の検索方法
[opc@linux ~]$ seq 100 | grep '8$' | xargs 8 18 28 38 48 58 68 78 88 98
問4.8が付く2桁以上の場合の検索方法
[opc@linux ~]$ seq 100 | grep '8.' | xargs 80 81 82 83 84 85 86 87 88 89
問5.1で始まり0が0個以上続く場合の検索方法
[opc@linux ~]$ seq 100 | grep '^10*$' | xargs 1 10 100
問6.偶数のみ検索する方法
[02468]$はの中に書いた時のどれか1文字を表します。
そして$で行末がの中の書いた文字という意味になります。
[opc@linux ~]$ seq 100 | grep '[02468]$' | xargs 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 100
問 7.基数のみ検索する方法
問6に^を付けることでことで奇数のみとできます。^は中に書いた文字以外となります。
[opc@linux ~]$ seq 100 | grep '[^02468]' | xargs 1 3 5 7 9 10 11 12 13 14 15 16 17 18 19 21 23 25 27 29 30 31 32 33 34 35 36 37 38 39 41 43 45 47 49 50 51 52 53 54 55 56 57 58 59 61 63 65 67 69 70 71 72 73 74 75 76 77 78 79 81 83 85 87 89 90 91 92 93 94 95 96 97 98 99 100
問 8.ゾロ目を検索する方法
^(.)は先頭の文字に番号を付けます。\1で再度^(.)で取得した値を繰り返します。
最後に$をつけることで行末指定をします。
[opc@linux ~]$ seq 100 | grep -E '^(.)\1$' | xargs 11 22 33 44 55 66 77 88 99
問 9.田で終わる文字を検索する方法
grep -o "[^ ]田"でスペースではない1文字の後ろに田が付くものを検索している
[opc@linux ~]$ echo 中村 山田 田代 上田 | grep -o "[^ ]田" 山田 上田